Intro
In an age where Jr. devs are expected to know how to run fully scaled SaaS and Social Media platforms and have the wisdom that realistically should only be drawn from experienced seniors…UGH. Let’s go over the basics that should be enough to fool the oblivious recruiters.
Premise
Imagine you’re tasked with building a social media app for millions of users, a simple server and database won’t scale at all. This calls for a DistributedSystem.
Distributed Systems
A network of independent servers (actual computers or VMs) that work together to manage the immense task loads, combined they work as one coherent system.
We need to understand the key characteristics of this system.
Scalability
Refers to the system’s ability to handle a increasing work load. There are two types of scaling.
- Horizontal: adding more servers and machines
- Vertical: adding more resources. // Upgrading the machines.
Reliability
System must continue to function even when components fail. Minimizing downtime is the main objective, which leads us to Availability.
Availability
This characteristic refers to the percentage of time in which the system is operational without faults.
Efficiency
Refers to the latency (delay till first response) and throughput (number of operations per unit of time) of the system.
Trade off
Realistically the perfect system doesn’t exist, it’s a trade-off between scalability and consistency.
Limitation
DistributedSystem are limited in their ability to be consistent, available, and partition tolerant.
The CAP theorem reflects this best. It states that a system can only achieve two at any given time. // The perfect system doesn't exist.
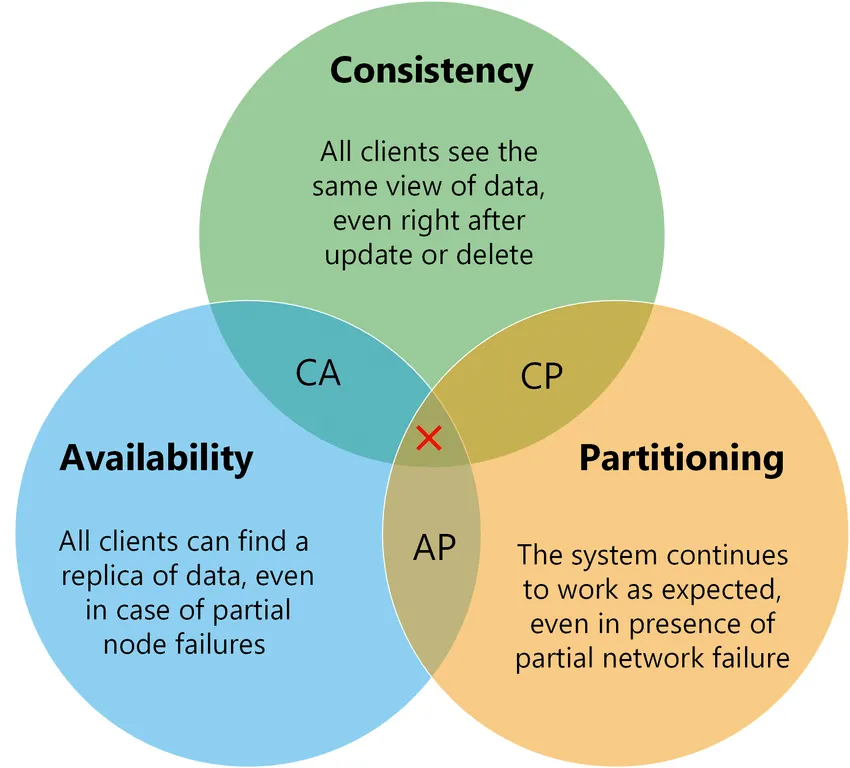
It’s crucial to consider this trade off and will affect how successful a system is.
Okay, this is great and all but to manage all the incoming tasks and requests, we need something to balance the load between the machines in our DistributedSystem.
Load Balancers
It’s all in the name, it distributes the incoming requests across multiple servers in our distributed system to prevent overwhelming any single server. If a server goes down, the LoadBalancer will manage redirecting the traffic to healthy servers.
Placement location
Load balancers fit in many slots. Common positions include:
- Between users and web servers
- Between web servers and application servers
- Between application servers and database servers. Basically anywhere you need to manage incoming traffic…
Algorithms used
Load balancers use algorithms to distribute the incoming requests, and a balancer may use more than one at a time. Common algorithms include:
Least Connection
Sends traffic and requests to the server with the least number of active connections.
Round Robin
A common technique in JobQueuing in which the servers take turns. Meaning the load balancer goes around distributing jobs sequentially.
IP Hash
This one utilizes the user’s IP address and feeds it into a HashingAlgorithm to determine which server handles the request. Similar concept to how Hashtables and HashMap work.
Point of Failure?
What if the Load Balancer itself fails? Simply add another one that’s on standby, to take over if the primary fails.
Caching
When many incoming requests are for the same data over and over again it creates unnecessary compute and loads. Read more here Caching Content Delivery Networks ( CDN) are another solution for serving static media quickly to users. They store commonly requested content closer to the user (geographically) to reduce latency.
Storage
Storage is another consideration when designing systems. There are many different database types, dialects, and predefined schemas to consider. It all comes down to what the needs of the system are. Relational Databases & SQL NoSQL
When considering between SQL and NoSQL we need to consider structure and schemas, querying languages and performance, scalability
A quick comparison:
| Category | SQL | NoSQL |
|---|---|---|
| Structure | Rigid schema | Flexible schema |
| Querying | SQL | document-collection focused |
| Scalibility | Vertical (horizontally via “Sharting”) | Horizontal |
| Reliability | ACID compliant | Not ACID compliant (due to performance compromise) |
ACID principles
ACID refers to the following DB principles:
- Atomicity: transactions are fully completed or not at all.
- Consistency: transactions take DB from one valid data-state to another, while enforcing schemas and defined rules.
- Isolation: transactions don’t interfere with each other .
- Durability: ensures that once a transaction is completed, it remains permanent even in case of failure.
Data Indexing
Querying data in an SQL DB is rather slow, every request needs to go through the collections and find the records. #DBIndexes create a separate DataStructure that points to the location of the actual data in the DB, sorta like a Map to speed up queries.
Common indexes:
- Primary Keys/UID
- Non-primary key columns such as names
- Composite index (multiple columns of non-UID) // very useful for queries that bundle these columns frequently like fname, lname, and email.
Index Trade off
While it can speed up read and search operations, it can slow down write operations. Due to the need to update the index when the data is updated…
Data Partitioning
When data storage grows to a point where veritcal scaling can longer solve the issue, DataPartition is needed.
This technique decomposes large databases into smaller more focused and specialized databases. These manageable DBs improve performance, availability, and load balancing.
Types
Horizontal Partitioning (Sharding)
Divides rows of a table across multiple DBs.
Vertical Partitioning
Separates entire features/items or columns into separate DBs.
Directory-Based Partitioning
Uses a directory and look-up service to abstract the partitioning schema.
Techniques
Hash based
Uses a hash function on a key-attribute of the data to determine which partition the data belongs to
Consistent Hashing
Minimizes data redistribution when scaling number of servers, by spreading the data across several servers using a hash function. Each server manages a portion of the hash-range, so adding/removing servers means only a small portion needs to be remapped.
List Partitioning
Assigns each partition a list of values. So data is stored based on the list key it belongs to.
Round Robin
Distributes data by cycling through the partitions
Composite
Combines 2+ techniques.
Challenges
Difficulty joining data across partitions can lead to issues with data rebalancing.
Final form
When all that’s combined we get something resembling
flowchart LR subgraph Users U1([User]) U2([User]) U3([User]) U4([User]) end U1 --> LB U2 --> LB U3 --> LB U4 --> LB LB([Load Balancer]) --> S1 LB --> S2 LB --> S3 subgraph Servers S1([Server 1]) S2([Server 2]) S3([Server 3]) Redis[[Redis Cache]] Redis -.-> S1 Redis -.-> S2 Redis -.-> S3 end S1 --> DB S2 --> DB S3 --> DB subgraph Databases DB1([Database]) DB2([Database]) DB3([Database]) DB end S1 --> DB1 S2 --> DB2 S3 --> DB3
